The long Easter weekend finally bought me some time to deal with Computer Vision – a super interesting topic – unfortunately with a rather flat learning curve as I think. This was also my first contact with Python.
Quite fast I came across the page https://www.pyimagesearch.com. Adrian Rosebrock writes incredibly good tutorials on this topic.
After working through some of the tutorials I came across his tutorial where he built a people counting system using OpenCV. This is a pretty exciting topic that we will surely come across more often in the future, for example when we are only allowed to let a limited number of people into buildings or areas due to infection protection reasons.
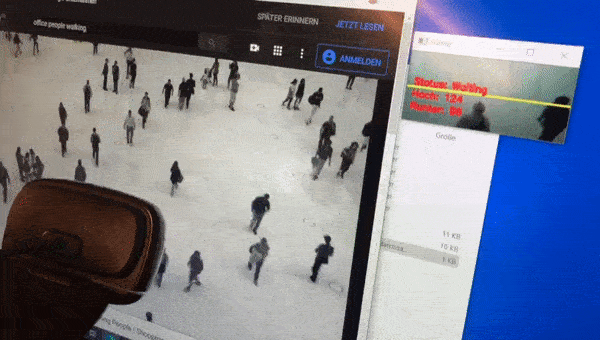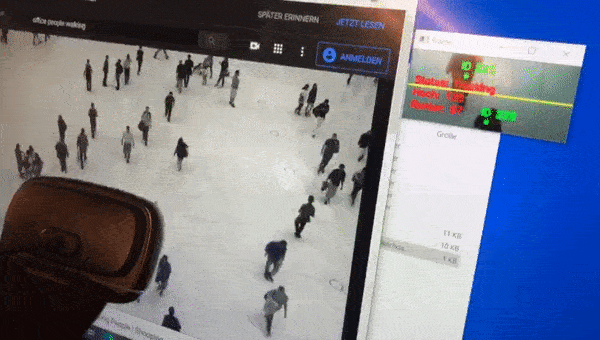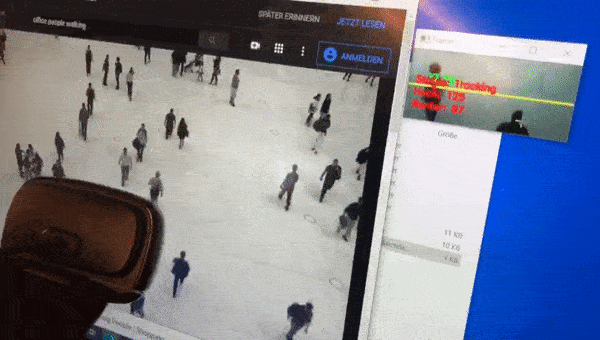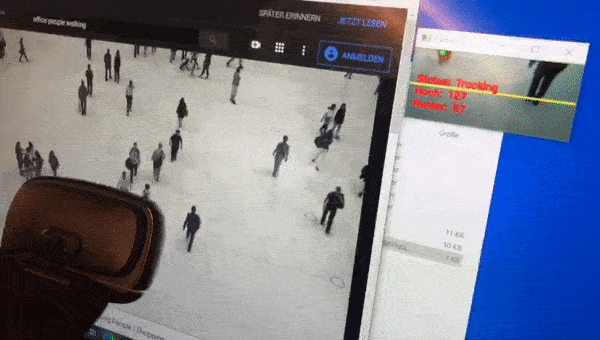
People counting is generally an exciting field. You might think that this is a common problem now, but the longer I work on it the bigger and more difficult it looks to me. If you count the number of door openings in retail, you don’t know how many people pass through. If you count with the help of a height profile scanner you cannot distinguish children from full shopping carts. A simple light barrier cannot distinguish the shopping trolley from people and people passing next to each other are also only counted once. Passive infrared sensors can only count movements, not the number of people. Laser scanners are relatively expensive.
Computervision seems to be a good approach because here you can search for persons with training data. But unfortunately there are many, many pitfalls.
Computervision is an interesting matter from a data protection point of view. The object recognition happens locally. No image or video has to leave the PC and after a single frame has been sent through the neuroyal network it is discarded. No image or information traceable to a person remains on the computer. No face recognition is done (in this case) but only a person recognition: Does the object look more than 50% similar to a person? Yes/no.
Of course, one can still argue about the acceptance of a camera.
The computer vision with OpenCV that Adrian offers on his website works pretty well out of the box. I would say that I had a 70% positive detection rate with a simple webcam right after the initial setup. But if you consider that 30% of the people were either not recognized or were counted several times, this is not a very good result if you want to monitor the entrance area of a restaurant room where only 100 people are allowed to enter. +-30 persons and in the worst case even drifting in one direction is worse than a person just switching a traffic light to red or green at the entrance area from time to time.
Sometimes I walk up and down the picture myself or I just show my webcam a video stream on YouTube with people walking around.
What is missing for a 95% detection rate that would be acceptable to me?
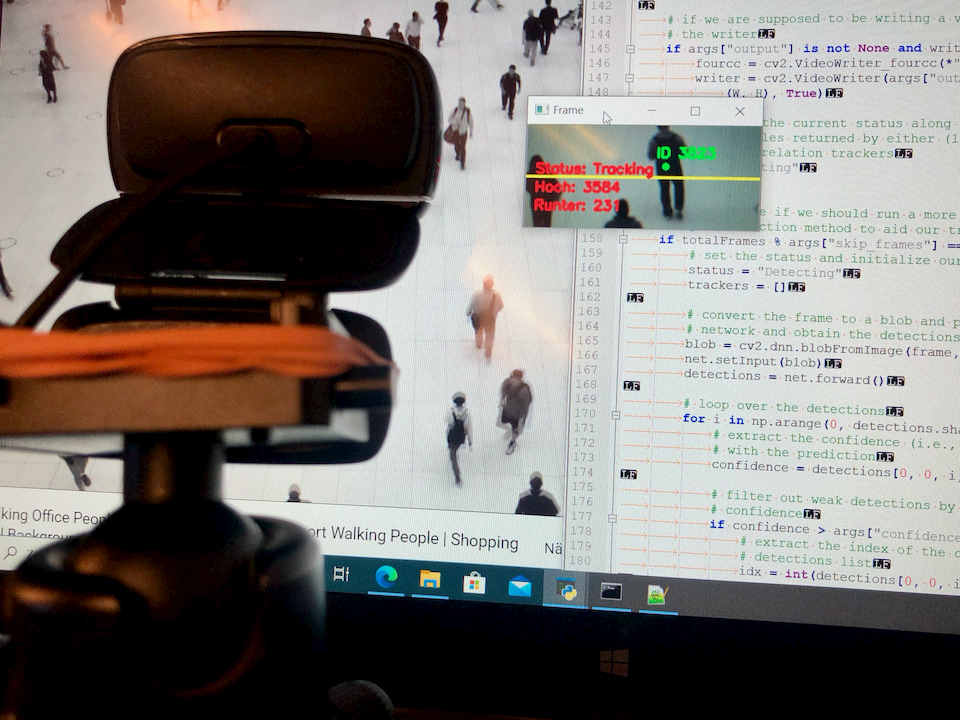
I’ll have to back up a little. The people count happens in two steps. Every X frames an object detection on persons is started in the video stream. All objects that look like a person to a certain (adjustable) percentage are detected and marked. In all other frames a tracking of the detected persons is done. The persons are tracked with a tracker from the moment they are detected until they leave the frame.
But where are the difficulties now?
Person recognition
The person recognition works amazingly well! MUCH too well if I am honest.
Why am I not satisfied with that, you ask yourself?
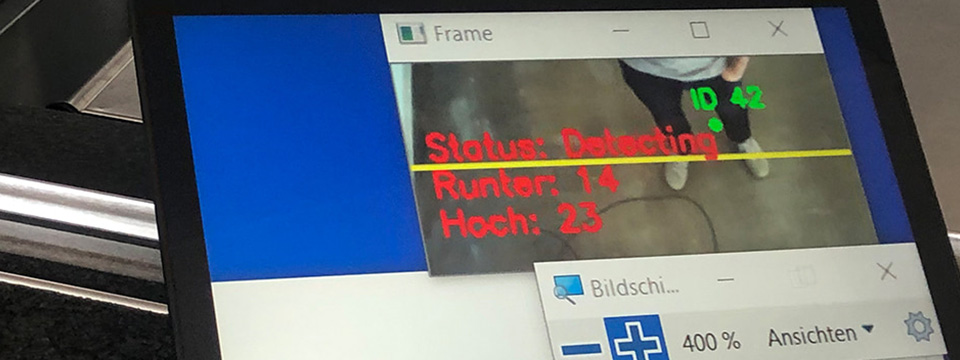
Depending on the angle at which the persons are photographed, either the legs or the head appear first in the picture. Both are incredibly well recognized. Let us assume that the feet are recognized first. Then the tracker follows the feet. While the person is walking through the picture the tracker loses the view to the feet and stops tracking. In a subsequent person recognition cycle the rest of the upper body of the same person or the head is recognized and traced further. So there is a good chance that a person is recognized several times while walking through the picture.
The camera perspective and focal length are therefore extremely important. If the person is too large in the detection area, he or she will be detected more often. If the person is too small or the angle is too steep, he or she will not be recognized due to the unknown contour.
It would be interesting to see how some commercial providers use head recognition. Unfortunately, I do not have a corresponding neural network with which I could work.
Tracking
Tracking is one of my biggest concerns. Unfortunately, it often happens that a person who walks too “close” to the webcam is counted several times. First the legs, then the legs disappear and then at the last moment the upper body is recognized as a new person and a person is counted twice. The tracker sticks to the middle of the first detected object. Unfortunately, it cannot drift and use new information from the neuroyal network.
The tracker can be adjusted well with at least two parameters. The distance in which the tracker searches for the same object between the images and the time the tracker may lose an object until it “forgets” the object. These two parameters have to be reconsidered for each situation. Factors that play a role here are how fast the people walk through the image, how fast the frame rate of the image processing takes place in the tracking cycle and whether people like to “cross” or overlap through the image. It can also happen that a tracker is passed from one person to another. For example, if a person leaves the image in the upper left corner and comes back from the same position shortly afterwards, this new person can take over the old tracker. A problem because every tracker has a unique ID and each ID is counted only once. So the tracking object of the new person is not able to be counted.
Up/down detection
Adrian divides the image into two areas and looks at the Y-coordinate between two tracker positions. If a tracker moves up in the upper part of the image, a “up” is counted. The tracker is “burned” and cannot trigger another count. Simple but unfortunately too simple.
Because the trackers have a little problem. They are shaking/jumping around the tracked object a bit. If a person walks very slowly through the picture it can happen that the tracker jumps in the opposite direction at the very beginning and counts in the opposite direction before the person reaches the “correct” counting area.
Adrian looks at an “average” of the running direction which becomes more and more accurate with a longer tracking time. But if the opposite jump to the running direction happens right at the beginning, the count for this object is broken before a proper average can be calculated.
I solve this problem by first observing an object a few frames before processing the Y-coordinates. This way I achieve a more reliable average of the Y-direction.
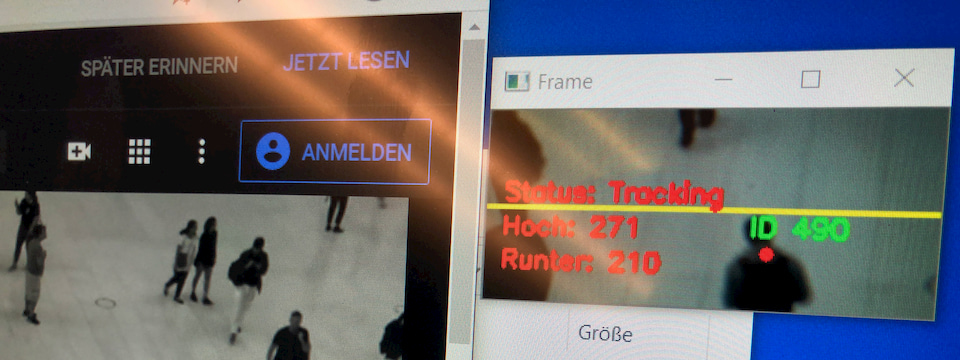
I build up three states that a tracking device can have:
- Red = Object was detected, but is only 0 to approx. 10 frames “old” Each position is recorded.
- Blue = Object is older than 10 frames and it is able to trigger a counting process in the upper or lower image area. Each position is recorded
- Green = Object has been counted and is no longer countable from that moment on.
Red 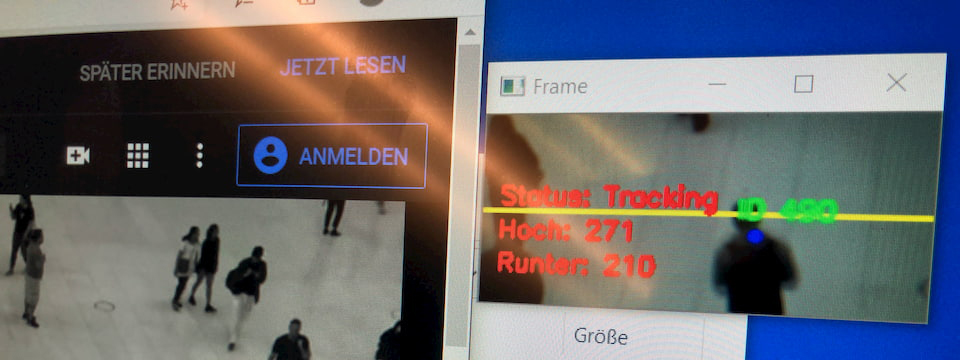
Blue 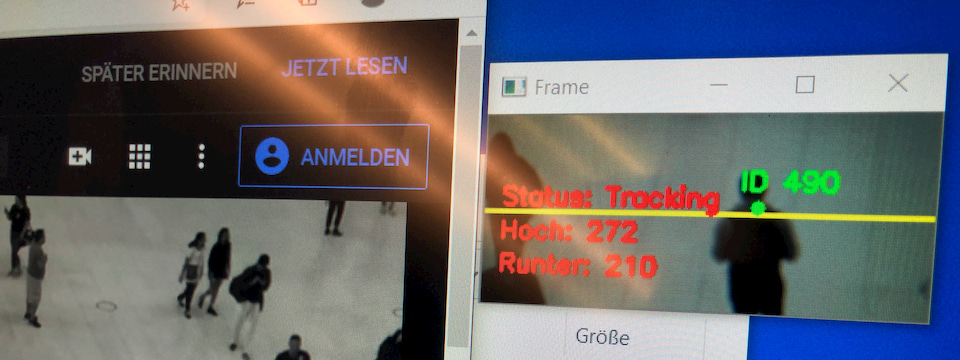
Green
The camera
Currently I use a simple webcam for image recognition. Resolution is not very important. I cropped out a smaller image from the whole image to have less computing power for the image recognition. So a better tracking and a faster image recognition are possible. In general I am surprised how little image information the neural network needs to recognize a person.
One problem is that I have no influence on the exposure of the camera. The camera sets itself accordingly bright or dark depending on the light situation. If I only process a smaller part of a larger image, I have to make sure that the exposure is ok for the respective part. With my Logitech there is no chance for external correction. OpenCV offers this option but the camera ignores the commands – a known problem with most webcams. A camera with variable focal length and focus fixation would also be nice. I thought of something like this: Adjustable zoom and focus 5-50mm or Adjustable zoom and focus 2.8-12mm. The parts would give me flexibility in use and eliminate the focus pumping my current webcam does from time to time.
What happens next?
The project is a lot of fun and slowly the learning curve is getting higher. I will find a scenario where I can test the project in the wild. I will try to adjust all parameters for this location until I get a detection rate of hopefully 90-95%. At the same time I will try to find a better tracking algorithm. I hope I can report positive results soon.
Hi,
Thanks for the detailed review on the project. It was very helpful to take things into consideration for a stable solution. I haven followed your up/down adjustments and have found good results! however I would like to also implement the red,blue and green dot that you have implemented that looks cool and gives the idea that the logic is working. I have made a simple box around the detected person,green color for the detection part and blue color for tracking part. That thing of red,blue and green dots that you have done, I couldn’t find in the source code to edit. Also I have the limitation that I am using dlib as precompiled wheel file as I couldn’t get the error fixed while installing the source code of dlib with pip.
Would it be possible to share bits of your code to give us the idea how you did it?
Any help would be appreciated!
Can you share the algorithm and how you deploy the system. That would be helpful for me since I`m currently working out on this kind of system for my Research with Raspberry Pi. Thanks!